Der älteste Witz des bekannten Webdev-Universums besteht darin, dass es nicht komplett trivial ist, Elemente mit CSS vertikal zu zentrieren. Dieser Witz ist spätestens seit Frühjahr 2021, als mit dem Internet Explorer 11 der letzte nicht perfekt Flexbox unterstützende Browser auf das Abstellgleis befördert wurde, hinfällig. Seither, so wissen wir alle, könnte es einfacher nicht sein:
.wrapper {
display: flex;
align-items: center;
}
Flexbox (und Grid) bieten direkte Unterstützung für vertikale Zentrierung und das Problem ist damit ein für allemal komplett erschlagen. Außer per Flexbox und Grid ist Zentrierung außerdem mit absoluter Positionierung und einer Transformation zu erreichen. Dieses Verfahren braucht ein paar Zeilen mehr, ist dafür aber auf dem zu zentrierenden Element statt auf dessen Container anzuwenden:
.wrapper {
position: relative;
}
.element {
position: absolute;
top: 50%;
transform: translateY(-50%);
}
Diese Variante, die sich zunutze macht, dass sich Prozentangaben bei Transformationen auf die Maße des Elements statt auf die des Containers beziehen, hat den Vorteil, dass durch die Angabe von left und translateX en passant auch eine horizontale Zentrierung zu machen ist. Beide Varianten funktionieren ganz ausgezeichnet … solange das zu zentrierende Element kleiner (für vertikale Zentrierung: weniger hoch) ist, als sein Elternelement. Aber was, wenn nicht?
Vertikale Zentrierung schlägt Scrollbalken
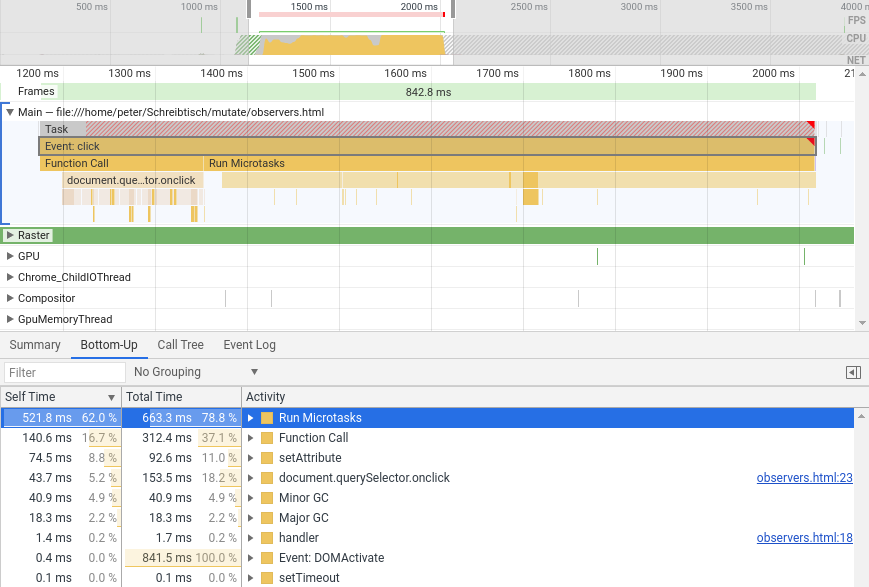
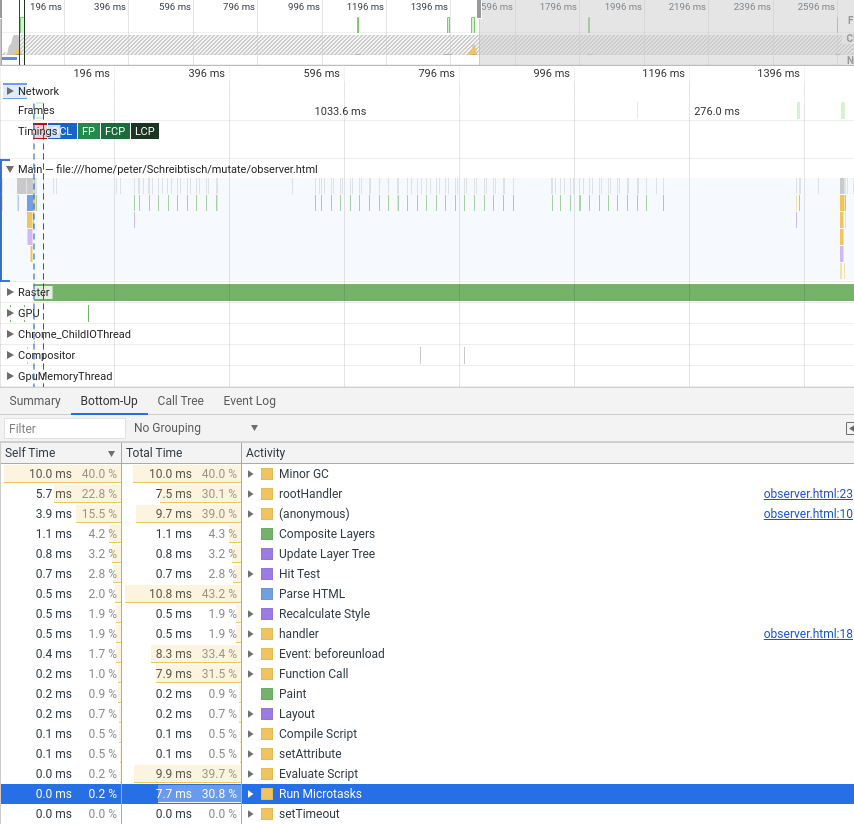
Nehmen wir einmal an, wir wollten ein Element variabler Größe innerhalb eines Containers darstellen. Das Element soll in unserem Beispiel vertikal zentriert sein, solange dafür der Platz ausreicht und wenn der Container für sein Element zu klein ist, sollen Scrollbalken auf dem Container die Möglichkeit bieten, das komplette Element zu betrachten. Auf diese Weise könnte etwa ein Grafikprogramm, bei kleinen Zoomstufen die gesamte Malfläche darstellen und bei starker Vergrößerung vertikales und/oder horizontales Scrollen ermöglichen.
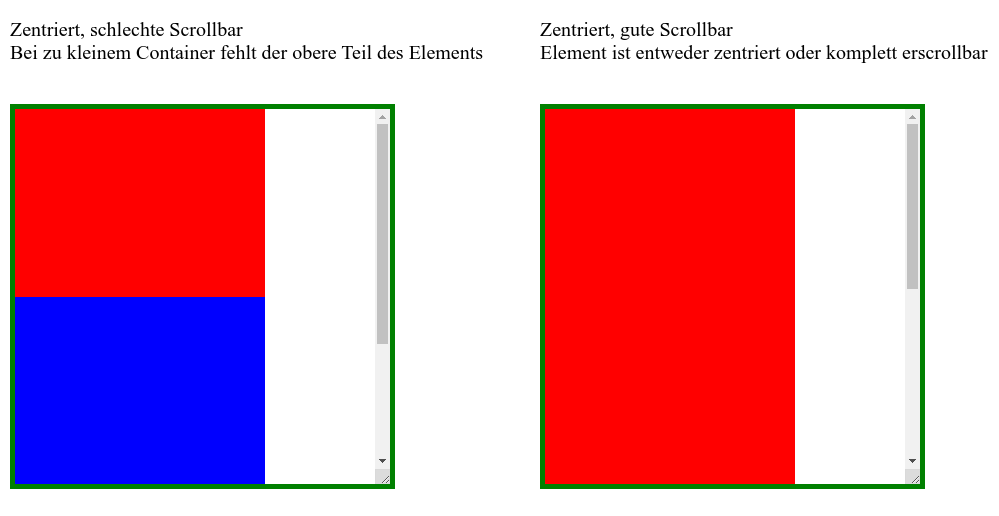
Das klingt zunächst ganz einfach, Scrollbalken in Webseiten sind schließlich kein Hexenwerk: Wir müssen nur dem Container overflow:auto verpassen, und schon taucht (wenn nötig) das gewünschte Scroll-UI auf. Problem gelöst! Es sei denn, wir wollen scrollen und vertikal zentrieren:
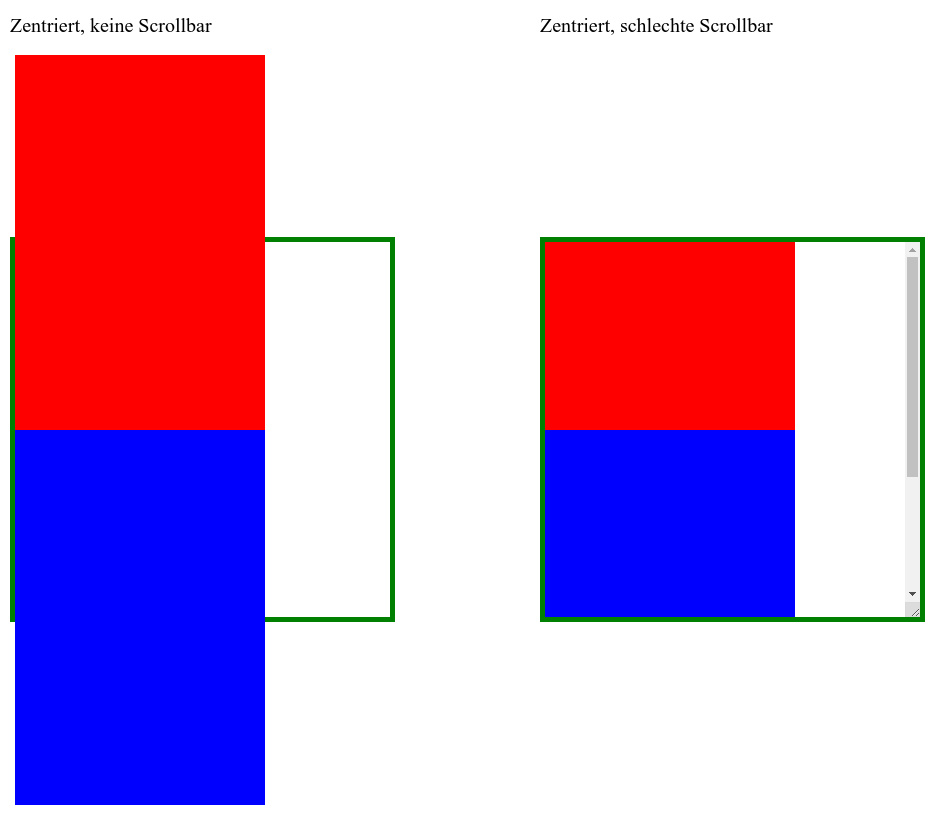
Das sieht gar nicht mal so gut aus! Die horizontale CSS-Zentrierung ist offenbar unverwüstlich und zentriert auch das, was eigentlich nicht mehr in seinen Container passt. Die Mitte des Containers und die Mitte des zu zentrierenden Elements (die Rot-Blau-Grenze) liegen aufeinander und wenn der Container weniger hoch als sein Inhalt ist, läuft es oben und unten über die Grenze seines Elternelements. So weit, so erwartbar. Der mit overflow: auto hinzugefügte Scrollbalken macht aber nur den unteren über den Rand laufenden Teil des zu großen Elements erschließbar! Alles, was oben übersteht, der gesamte überstehende rote Anteil, wird einfach abgeschnitten und ist komplett unerreichbar (man achte auf die Scroll-Position des rechten Containers im obigen Bild). Möglicherweise wichtiger Inhalt verschwindet auf diese Weise komplett im Overflow-Orkus. Das kann so nicht bleiben!
Eine Formel für bedingte vertikale Zentrierung … mit Nachteilen
Um unser Ursprungsziel zu erreichen, benötigen wir im Prinzip eine bedingte vertikale Zentrierung, die nur bei ausreichend Platz greift. Sobald der zu zentrierende Inhalt zu groß für seinen Container wird, muss der Zentrierungsmechanismus seine Arbeit einstellen und das Element normal an die obere linke Ecke seines Containers andocken, damit der Scrollbalken seine Arbeit verrichten kann. Am einfachsten geht das, indem wir
- Anstelle von Flexbox oder Grid als Zentrierungsmechanismus
position:absolutewählen topmithilfe voncalc()errechnen, statt einfachtop:50%zu verwenden und für die Maße des Elements mittransform: translateY(-50%)zu kompensieren- Einen Top-Overflow unterbinden, indem wir das
calc()-Ergebnis aus Schritt 2 mithilfe vonmax()auf mindestens0pxbeschränken
.element {
top: max(0px, calc((100% - 600px) / 2));
}
Der erste Parameter für max() ist der für uns nicht zu unterschreitende Top-Offset von 0px, während der zweite Parameter unser eigentlicher Wunsch-Offset ist. Für vertikale Zentrierung ist das die Hälfte des Platzes, der übrig bleibt, wenn wir von der Höhe des Containers (100%) die Höhe des zu zentrierenden Elements (im Beispiel 600px) abziehen. Das Ergebnis des calc()-Ausdrucks wird negativ, wenn des zu zentrierende Element höher als sein Container ist, aber vor diesen Auswirkungen bewahrt uns die Limitierung auf mindestens 0px. Im schlimmsten Fall, bei zu wenig Platz, dockt das Element also oben an und ist auf ganzer Höhe erscrollbar.
Der Haken an dieser Lösung: die Maße des zu zentrierenden Elements müssen bekannt sein. Prozentangaben in top beziehen sich auf das Elternelement und können sich auch auf nichts anderes beziehen; durch die Angaben wie top (ggf. kombiniert mit left, bottom und right) ergeben sich die Maße des Elements schließlich erst. Die Höhe des bedingt zu zentrierenden Elements müssen wir also kennen und in die „Formel“ für top eintragen.
Grundsätzlich könnten wir die top-Formel auch in der transform-Eigenschaft verwenden, haben dort dann aber das umgekehrte Problem: Wir müssten die Dimensionen des Elternelements kennen und fest eintragen. Prozentangaben in transform-Werten beziehen sich auf das betroffene Element selbst, denn eine Transformation ist nur eine Veränderung des Koordinatensystems für die zu zeichnenden Pixel. Deshalb bleibt der „Platzverbrauch“ eines Elements vor und nach einer Transformation gleich; die Pixel sind transformiert, doch das CSS-Layout bleibt, wie es war:

Egal ob wir die Verschiebung des Elements per Transformation oder per top versuchen, komplette Flexibilität ist nicht drin entweder, die Maße des Containers oder des zu zentrierenden Kindelements müssen wir kennen. Es sei denn, wir verwenden ein ganz bestimmtes Feature aus dem Dunstkreis der nagelneuen Container Queries!
Eine flexiblere Formel für bedingte vertikale Zentrierung
Container Queries sind im Prinzip Media Queries für Elemente – Queries, die sich nicht auf der Maße des Bildschirms, sondern auf die Eigenschaften ausgewählter Elternelemente (der Query Container) beziehen. Container Queries sind aber nicht einfach nur ein Standard für besseres Responsive Design, sondern führen auch eine Reihe von interessanten neuen Einheiten ein:
cqw: 1% der Breite eines Query Containerscqh: 1% der Höhe eines Query Containerscqi/cqb: 1% Der Inline- bzw. Block-Größe eines Query Containerscqmin/cqmax: Der kleinere bzw. größere Wert voncqiundcqb
Das bedeutet: in einer CSS-Transformation eines Elements haben wir, wenn sein Elternelement ein Query-Container ist, sowohl die Maße des Elements selbst (als %) als auch die des Elternelements (als cqw bzw. cqh) zur Hand! Die top-Formel, entsprechend adaptiert und in transform verwendet, kann damit das Element in eine zentrierte Position verschieben. Das Elternelement muss nur noch zum Query-Container erklärt werden (damit sich cqw und cqh auf etwas beziehen können) und schon klappt es:
.wrapper {
container-type: size; /* Maße von .wrapper definieren cqh/cqw */
overflow: auto;
}
.wrapper .element {
transform: translateY(max(0%, calc((100cqh - 100%) / 2)));
}
Selbst wenn sich die Maße von Container oder Content ändern, das Element bleibt zentriert und die Scrollbalken greifen, wenn nötig, ein! Besonders charmant finde ich an dieser Lösung den Grund für das Erscheinen und Verschwinden der Scrollbalken. Das Element wird zwar zentriert, doch da dies per Transformation geschieht, manifestiert sich der „Platzverbrauch“ des zentrierten Elements durchgehend an der linken oberen Ecke. Wird das Elternelement zu klein, findet sich auch die Transformation der Darstellung an dieser Position ein und - da ab dann der Platzverbrauch auch größer als der umgebende Container ist - die Scrollbalken tauchen auf. Keine Tricks jenseits der Transformation notwendig!
Fazit, Nachteile und Browserunterstützung
Wo sind die Haken bei dieser Lösung? Container Queries fehlen stand Dezember 2022 noch im Firefox. Support im Nightly Build ist schon da, aber noch nicht im regulären Release. Die Transformation bildet natürlich einen neuen Stacking Context und die Angabe von container-type auf dem Wrapper-Element aktiviert implizites Layout-, Style-, und Size-Containment. Das alles, abgesehen vom Firefox-Support, sind keine echten Haken, sondern fallen eher in die Kategorie der zu beachtenden Dinge. Ein reiner Selbstläufer ist das vertikale Zentrieren mit CSS dann doch nicht, jedenfalls nicht, wenn Scrollbalken ins Spiel kommen. Der älteste Witz des bekannten Web-Universums ist und bleibt auch Ende 2022 noch ein ganz klein wenig relevant.