Ich bin die nächsten Wochen und Monate fast durchgehend auf Achse und das Gute daran ist: das meiste ist öffentlich! Wenn ihr euch mal original druckbetanken lassen möchtet, habe ich folgende Termine im Angebot:
11. - 13. September in München: HTML5-Camp. Drei mal 12 Stunden HTML5 am Tag. Wenn ihr meint, dass ihr das aushaltet, könnte das Camp was für euch sein. Das Programm auf der Webseite ist nicht meins, sondern das von den anderen Nasen die da auch Trainings machen. Ich mache lieber 2 Tage Programm on demand vor Ort mit abschließendem Workshop-Tag. Das Ganze findet nochmal vom 19. bis zum 21. November statt.
19. September in Hamburg: HTML5-Workshop bei der WebDev Con. Falls ihr wissen wollt, wie man mit Libraries, Frameworks viel HTML5 in kurzer Zeit eine kleine Grafikbearbeitungs-Webapp baut, seid ihr hier richtig. Es sind nicht mehr viele Plätze frei!
8. - 10. Oktober in München: HTML5-Schulung bei der Open Source School. Mein bewährtes dreitägiges HTML5-Standardprogramm stattet die Teilnehmer im Druckbetankungsverfahren mit so gut wie allem aus, was man zu HTML5 wissen muss. Von semantischem Markup bis hin zu Canvas-Frameworks ist alles dabei. Geboten wird ein großer Praxisanteil, kleine Arbeitsgruppen und ein Buch gibt es obendrein. Nächster folgender Termin ist der 5. - 9. November.
11. und 12. Oktober in München: CSS3 bei der Open Source School. Mein zweitägiges CSS3-Standardprogramm katapultiert die Teilnehmer in das CSS3-Zeitalter, in dem Webfonts und Farbverläufe fließen. Einen großer Praxisanteil, kleine Arbeitsgruppen und ein Buch als Bonus gibt es auch hier. Nächster folgender Termin ist der 10. und 11. November.
Am Samstag twitterte ich die Frage, ob es denn schon Generatoren für CSS-Gradients gäbe, die die neue, finale Syntax produzieren. Die Frage, was es denn da für eine neue finale Syntax gäbe, kam umgehend zahlreich zurück. Eigentlich ist die Antwort einfach: gemeint ist die ohne Vendor Prefixes auskommende Syntax, die im Firefox ab Version 16 und im IE ab Version 10 zur Verfügung steht. Aber ist es denn eine neue Syntax, wenn einfach nur die Vendor Prefixes entfernt werden? In diesem Fall schon, denn es werden in Zukunft bei den Farbverläufen eben nicht nur Prefixe entfernt …
#foo {
background: -webkit-gradient(linear, left top, left bottom, from(#00abeb), to(#fff), color-stop(0.5, #fff), color-stop(0.5, #66cc00));
}
Man benötigte innerhalb der -webkit-gradient()-Funktion einen ganzen Haufen weiterer Funktionen zur Definition der Farbpunkte, so dass man sich einen Wolf tippten musste. Die Verwirrung steigerte sich weiterhin dadurch, dass diese Funktion sowohl für lineare als auch für komplett anders funktionierende radiale Verläufe benutzt werden konnte.
Gute Idee, aber verbesserungswürdige Ausführung urteilte man bei Mozilla. Im Firefox tauchte eine leicht abgewandelte Syntax auf, die sich in Folge (mit Vendor-Prefix) in allen so gut wie allen Browsern durchsetzte:
Die Syntaxen für lineare und radiale Verläufe wurden in die Funktionen linear-gradient() und radial-gradient() aufgespalten und die Schreibweise für Farbpunkte wurde vereinfacht. Außerdem hatte man nun die Wahl, ob man die Verlaufsachse für lineare Verläufe über einen Winkel festlegen wollte oder sich auf die Angabe des Achs-Startpunkts beschränken wollte – der Endpunkt wäre dann die gegenüberliegende Ecke bzw. Seite des Elements geworden.
Obwohl diese Syntax sich am Ende (mit Präfix) in allen Browsern durchsetzte und ganz ohne Zweifel eine Verbesserung des Originalvorschlags war, so war sie doch nicht der Weisheit letzter Schluss. So ist z.B. die Lesbarkeit der Syntax für radiale Verläufe nicht optimal: um zu wissen, was 40% 10%, 200px 200px im obrigen Beispiel bedeutet, muss man sehr genau wissen, in welcher Reihenfolge Form-, Positions- und Größenparameter an radial-gradient() übergeben werden. Auch ist etwas seltsam, eine Verlaufsachse über ihren Startpunkt zu bestimmen, denn die meisten Menschen begreifen einen Verlaufs als etwas, das in eine bestimmte Richtung geht. Diese Richtung kann man natürlich aus dem Startpunkt schließen, aber umdenken muss man dafür trotzdem. Außerdem hatte das Webkit-Team bei seiner ursprünglichen Syntax die Winkel der Verlaufsachse als Polarkoordinaten definiert – ergo zeigt eine Achse mit dem Winkel 0° nach Osten bzw. Rechts und die Drehung der Achse erfolgte gegen den Uhrzeigersinn. Die überarbeitete Syntax übernahm diese Definition. Das Problem daran ist, dass sonst überall in CSS 0° als Norden bzw. Oben behandelt wird und eine Drehung mit dem Uhrzeigersinn schon ein gutes Stück intuitiver ist …
Ganz optimal war also auch die überarbeite Verlaufssyntax nicht geraten. Und da diese Syntax bisher nur mit Vendor-Prefix implementiert wurde, sah man beim W3C keinen Grund, von einer weiteren Überarbeitungsrunde Abstand zu nehmen. So entstand eine dritte, finale Syntaxrevision, die vom Firefox 16 und im IE 10 unterstützt (werden) wird.
Die Änderungen
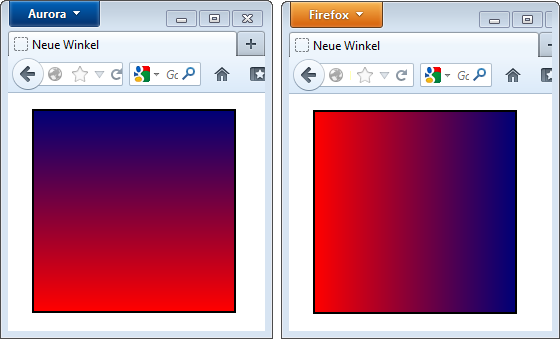
Die Winkelangaben bei linearen Verläufen legen für 0° jetzt Norden bzw. Oben an. Das passt besser zu Winkelangaben, wie sie im Rest von CSS3 vorkommen und sorgt direkt dafür, dass in Browsern wie dem Firefox 16 die Syntaxen mit und ohne Vendor-Prefix in ihren Auswirkungen nicht identisch sind:
#foo {
/* Vendor-Prefix = 0 Grad ist Osten */
background: -webkit-linear-gradient(0deg, #F00, #007);
background: -moz-linear-gradient(0deg, #F00, #007);
background: -o-linear-gradient(0deg, #F00, #007);
/* Kein Prefix = 0 Grad ist Norden */
background: linear-gradient(0deg, #F00, #007);
}
Der Firefox 16 (links) versteht unter 0° etwas anderes als der Firefox 14.
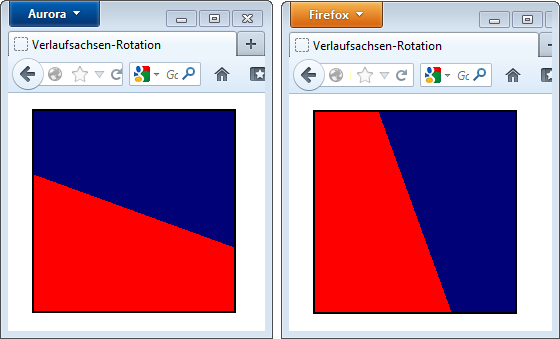
Die Rotation der Verlaufsachse lief in der alten Syntax gegen den Uhrzeigersinn und erfolgt in der neuen Syntax in die andere Richtung:
#foo {
/* Vendor-Prefix = 0 Grad ist Osten, Rotation GEGEN den Uhrzeigersinn */
background: -webkit-linear-gradient(20deg, #F00, #F00 50%, #007 50%, #007);
background: -moz-linear-gradient(20deg, #F00, #F00 50%, #007 50%, #007);
background: -o-linear-gradient(20deg, #F00, #F00 50%, #007 50%, #007);
/* Kein Prefix = 0 Grad ist Norden, Rotation IM Uhrzeigersinn */
background: linear-gradient(20deg, #F00, #F00 50%, #007 50%, #007);
}
Der Firefox 16 (links) rotiert die Verlaufsachse im Uhrzeigersinn, der Firefox 14 anders herum.
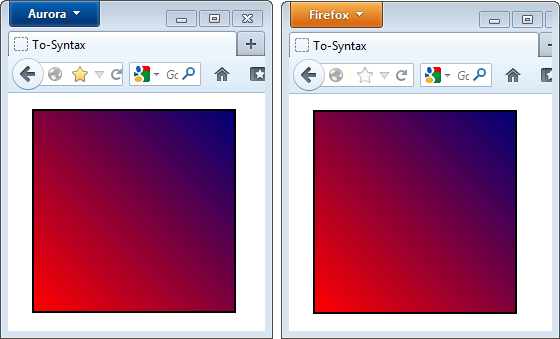
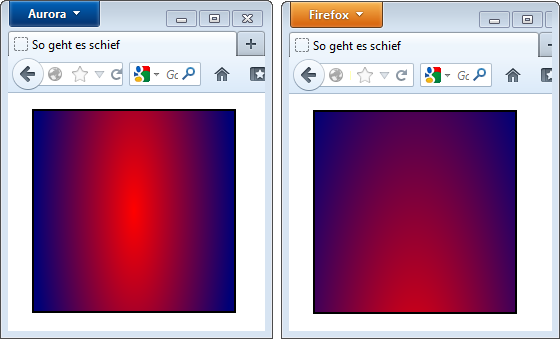
Bei Verlaufsachsen-Koordinaten für lineare Verläufe wird jetzt der End- statt des Startpunkts angegeben, mit dem Wörtchen to davor:
Der Firefox 16 (links) möchte den Endpunkt der Verlaufsachse haben, der Firefox 14 den Startpunkt.
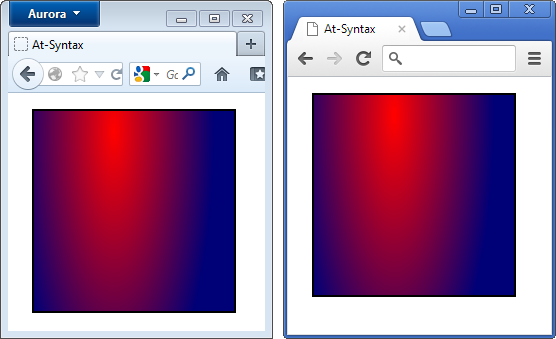
Den Koordinaten für radiale Verläufe wird das Wörtchen at vorangestellt. So ist die Koordinatenangaben leichter von Größenangeben unterscheidbar und die Syntax liest sich fast wie die englischsprachige Beschreibung des Verlaufs:
#foo {
/* Alte Syntax für eine 100*300-Ellipse bei 40% 10% */
background: -webkit-radial-gradient(40% 10%, 100px 300px, #F00, #007);
background: -moz-radial-gradient(40% 10%, 100px 300px, #F00, #007);
background: -o-radial-gradient(40% 10%, 100px 300px, #F00, #007);
/* Neue Syntax für eine 100*300-Ellipse bei 40% 10% */
background: radial-gradient(100px 300px at 40% 10%, #F00, #007);
}
Im Firefox 16 (links) folgen Positionsangaben zusammen mit dem Wörtchen at auf die Maßangaben, in allen älteren Browsern ist es umgekehrt und ohne Trennwort.
Wie macht man es nun richtig?
Die Syntaxen sind zwar grundsätzlich inkompatibel, aber das ist nicht weiter schlimm: die neue Syntax wird in IE 10 und Firefox 16 nur in der Schreibweise ohne Vendor-Prefix verwendet. Die Variante mit Vendor-Prefix bleibt in den neuen Browsern vorerst erhalten und hat auch weiterhin die alte Syntax. Da heißt, dass man völlig problemlos beide Varianten in einer CSS-Regel unterbringen kann, genau wie es die Codebeispiele in diesem Artikel machen. Einfach erst Hintergrund-Deklarationen mit Präfix und alter Syntax, danach die ohne Präfix und mit neuer Syntax.
Ein Problem könnte es höchstens geben, wenn man in vorauseilendem Gehorsam in seine Stylesheets bereits Gradients ohne Vendor-Prefix eingebaut hat, dort aber weiterhin die alte Syntax verwendet:
Ohne at hält der Firefox 16 (links) das, was im Firefox 14 eine Positionsangabe ist, für eine Größenangabe.
Aber so etwas macht ja niemand, oder?
Die gute Nachricht ist: es gibt tatsächlich schon einen Generator, der die neue Syntax produziert: der gute alte Ultimate CSS Gradient Generator. Man muss sich also den ganzen Syntax-Zirkus nicht merken wenn man die richtigen Tools an der Hand hat.
Ich bin zur Zeit viel unterwegs und komme nicht dazu, viel originelles zu schreiben. Also spielen wir einfach das altbekannte Spiel weiter: Leser fragen zu HTML5, CSS3, JavaScript und Co und der Erklärbär antwortet. Denn Fragen kommen jeden Tag bei mir an und weil die meisten dieser Fragen (und Antworten) viel zu schade sind, um sie in meinem E-Mail-Archiv verrotten zu lassen, hole ich sie im Rahmen der Artikelserie „Fragen zu HTML5 und Co“ regelmäßig ans Tageslicht – getreu dem Motto „dumme Fragen gibt es nicht“.
HTML5 in XHTML/HTML 4
Ich habe eine schöne HTML5-Seite gebaut mit schönen HTML5-Formularfeldern und so. Nun soll das Formular aber in eine HTML4/XHTML-Seite eingebunden werden und zwar direkt, nicht per <iframe>. Was kann im schlimmsten Fall passieren?
Passieren kann eigentlich gar nichts, die HTML5-Elemente dürften auch in Seiten mit anderen Doctypes funktionieren. Browsern sind Doctypes nämlich total egal. So lange der Browser in der prinzipiell Lage ist, ein Element zu verarbeiten, wird es tun, egal was in der ersten Zeile der HTML-Seite steht. Als kleine Demo: Ein Canvas-Element in einem Dokument mit dem Doctype HTML 3.2.
Wohlgemerkt: dass so etwas funktioniert, heißt nicht, dass man auch Gebrauch von dieser Möglichkeit machen sollte! Sofern es keine wirklich triftigen Gründe gibt, das HTML5-Formular in die Non-HTML5-Seite direkt einzubetten, sollte man es lassen – Webstandards gibt es nicht ohne Grund.
Das ist eine ganz normale Wechselwirkung zwischen Transformationen und dem Layering-Mechanismus von CSS. Die Spezifikationen lassen uns wissen:
This module defines a set of CSS properties that affect the visual rendering of elements to which those properties are applied [...] Some values of these properties result in the creation of a containing block, and/or the creation of a stacking context.
Zu deutsch: mit CSS3 transformierte Elemente bilden einen eigenen, geschlossenen Kontext (Stacking Context). Wenn man die in einem solchen Element enthaltenen Kindelemente mit einem Z-Index versieht, gilt dieser nur in Relation zu anderen Kindelementen des transformierten Elements. Dieser Effekt tritt auf, weil nicht wirklich das Element plus seine Kindelemente transformiert werden, sondern es wird durch den Browser ein Gesamtbild des Elements und seines Inhalts errechnet, das dann transformiert wird. Und damit wird der Z-Index eines Kindelements in Bezug auf Elemente außerhalb des Elternelements natürlich bedeutungslos.
Audio- und Videocodecs abfragen
Wir sind gerade dabei, das Video-Element in unsere Seite einzubauen und es funktioniert soweit ganz gut. Ich möchte jetzt aber eine Fehlermeldung ausgeben, wenn keins der angebotenen Video-Formate vom Browser akzeptiert wird. Welches JavaScript muss ich da drauf werfen? :-)
Ob ein Browser ein Audio- oder Video-Format unterstützt lässt sich herausfinden, indem man die JavaScript-Funktion canPlayType() auf einem Audio - oder Video-Element ausführt. An die Funktion kann mal als String den MIME-Type bzw. den Codec übergeben, auf dessen Unterstützung man prüfen möchte, also z.B. so:
Die Rückgabewerte dieser Funktion sind entweder ein leerer String (Format wird nicht unterstützt) oder der String "maybe" oder der String "probably". Das mutet etwas kurios an, ist aber eigentlich sowohl sinnvoll als auch praktisch.
Zum einen weiß der Browser unter Umständen wirklich nicht sicher, ob er etwas mit dem übergebenen Format anfangen kann. Wenn man z.B. Chrome 20 nach seine Unterstützung für "video/mp4" fragt, antwortet er "maybe", weil er aus dem MIME-Type allein nicht schließen kann, mit welcher Codec-Version er es zu tun bekommen wird. Zwar kann er prinzipiell etwas mit MP4-Dateien anfangen, aber ganz sicher sein kann sich der Browser ohne weitere Informationen eben nicht. Fügt man eine Codec-Angabe hinzu und fragt z.B. nach "video/mp4; codecs='avc1.42E01E'" (H.256 Baseline) kommt ein zuversichtlicheres "probably" zurück, denn jetzt weiß der Browser schon sehr viel genauer, was da auf ihn zukommt und er kann einschätzen, ob sein Codec-Fundus der Aufgabe gewachsen ist.
Außerdem haben Stings als Rückgabewerte den Vorteil, dass man Sie in JavaScript entweder sehr genau oder nur ungefähr unterscheiden kann, je nachdem was man möchte. Möchte man man sowohl "maybe" als auch "probably" als Antworten akzeptieren, ist die entsprechende If-Abfrage ganz einfach:
var canPlay = myVideo.canPlayType('video/mp4');
if(canPlay){
macheEtwas();
}
Die Funktion macheEtwas() wird hier sowohl bei "maybe" als auch bei "probably" ausgeführt, da beide Strings als true durchgehen, der leere String (die negative Antwort von canPlayType()) gilt hingegen als false. Möchte man es hingegen genau nehmen und nur "probably" durchlassen, so ist das gar kein Problem:
var canPlay = myVideo.canPlayType('video/mp4');
if(canPlay === "probably"){
macheEtwas();
}
Was auf den ersten Blick so kurios daher kommt, ist also eigentlich ganz patent.
Welches Element für Kommentare?
Wenn ich nach semantischem Markup für Kommentare suche, wird immer mit <article> pro Kommentar gearbeitet. Mir erschließt sich der Sinn dafür allerdings nicht. Ich finde eine <ol>-Liste wesentlich korrekter dafür. Wie siehst du das?
Ich persönlich halte beides für Varianten, die man einsetzen kann, je nach Situation. Die Spezifikationen scheinen recht eindeutig zu sein, denn sie erwähnen in ihrer Definition des <article>-Elements explizit Nutzerkommentare als möglichen Anwendungsbereich:
The article element represents a self-contained composition in a document, page, application, or site and that is, in principle, independently distributable or reusable, e.g. in syndication. This could be a forum post, a magazine or newspaper article, a blog entry, a user-submitted comment, an interactive widget or gadget, or any other independent item of content.
Aber jetzt bleibt natürlich die Frage, ob ein Nutzerkommentar tatsächlich eine self-contained composition und ein independent item of content ist. Und das, würde ich mal sagen, hängt von der betroffenen Webseite bzw. von dem Inhalt der dort produzierten Nutzerkommentare ab. Wenn wir uns z.B. eins der Werke von Ahoi Polloi ansehen, sind die Kommentare dort eher kurz und ohne den Kontext des besprochenen Haupt-Posts unverständlich. Ich denke nicht, dass ein Statement wie Hoil Polloi! eine self-contained composition und ein independent item of content ist. Wenn wir hingegen schauen, was die Besucher bei Stefan Niggemeier an Kommentaren hinterlassen, sieht die Lage anders aus. Ich zitiere mal Kommentar Nummer 7 aus Kein schöner Lanz:
Lanz führt die Tradition von Kerner fort. Besser noch, er hat dessen Stil perfektioniert. Genau dieses Talent hat das ZDF gesucht. Wir sprechen hier immerhin von einer Kernzielgruppe 50 +. Die wollen nicht denken, die wollen berieselt werden. Am besten von einem Schwiegersohn Marke Lanz oder Pilawa. Deshalb passt Lanz auch sehr gut zu Wetten dass. In diesem Sinne, kein Grund sich aufzuregen. Alles so gewollt. Alles gut. Immer diese Ansprüche …
Dieser Abschnitt könnte (wie die meisten Kommentare auf der Seite) ohne Probleme für sich allein stehen und ergibt auch ohne den Originalartikel so viel Sinn, dass man von self-contained composition und independent item of content sprechen kann.
Es ist wie immer bei der Semantik: es kommt darauf an, was man will. Nutzerkommentare bei Youtube oder auf /b/? Eher <ol>. Kommentare bei Zeit Online oder SPON? Eher <article>. Das ist jedenfalls meine Interpretation der Sache …
Weitere Fragen?
Eure Fragen zu HTML5, JavaScript und anderen Webtechnologien beantworte ich gerne! Einfach eine E-Mail schreiben oder Formspring bemühen und ein bisschen Geduld haben – falls ich gerade unterwegs bin, kann es mit Antwort manchmal etwas dauern, doch früher oder später schreibe ich garantiert zurück.
Als Erklärbär für HTML5 und andere Webtechnologien bekomme ich jede Woche neue Fragen rund um Webentwicklung gestellt. Da diese Fragen (und Antworten) viel zu schade sind, um sie in meinem E-Mail-Archiv verrotten zu lassen, hole ich sie im Rahmen der Artikelserie „Fragen zu HTML5 und Co“ regelmäßig ans Tageslicht – denn dumme Fragen gibt es schließlich nicht!
Slashes in selbstschließenden Elementen?
Mir ist noch nicht zu 100% klar, wie es sich mit HTML5 und selbstschließenden Elementen verhält. Sollte man diese gar nicht mehr verwenden? Also z.B. statt <input /> nur noch <input> und statt <br /> nur noch <br> verwenden? Ist es, wenn man ein sauberes HTML5-Dokument schreiben möchte, sinnvoll, weg von der XHTML-Syntax zu gehen? Oder ist es völlig egal?
HTML5 ist völlig egal, ob selbstschließende Tags mit einem Slash zugemacht werden oder nicht. Der HTML-Parser des Browser ignoriert den Slash komplett, denn dass es so etwas wie „Inhalt zwischen öffnendem und schließendem Input-Tag“ nicht gibt, ist fest in ihn einprogrammiert. Wenn der Slash aber vorhanden ist, ist er für den Browser reines Hintergrundrauschen und stört nicht groß.
Kurz gesagt ist ist <input /> aus Browser-Sicht genau so richtig wie <input>. Die einzig maßgebliche Entscheidungshilfe in dieser Frage sollte der Code-Standard des eigenen Teams oder Projekts sein.
Warum funktioniert Web Storage nicht?
Ich habe mir zur Einführung in HTML5 (speziell das Thema Local Storage) eine Notizbuch-Applikation aus dem Internet rausgesucht. Diese hat im Firefox, Opera und Chrome auch funktioniert, nur im Safari 5.1 und Internet Explorer 9 wurden die eingegebenen Werte nicht übernommen. Laut meiner Recherche sollte Local Storage aber in der jeweiligen Version vom Safari und Internet Explorer funktionieren. Javascript ist auch aktiviert. Wie kann das sein?
So etwas kann passieren, wenn eine Webseite nicht über einen Webserver, sondern über das lokale Dateisystem (file://) aufgerufen wird. Web Storage arbeitet, wie viele andere HTML5-Technologien auch, auf einer Pro-Origin-Basis. Die Daten werden getrennt nach Host, Protokoll und Port einer Webseite gespeichert, damit http://foo.de nicht die Daten von https://www.bar.com auslesen kann. Bei einem Aufruf über das lokale Dateisystem gibt es aber weder Host noch Protokoll noch Port –also keinen Origin – und einige Browser verweigern dann eben den Dienst. Das ist bei vielen HTML5-Technologien so, nicht nur bei Web Storage.
Mehrere Formular-Ziele mit HTML5
Gibt es in HTML5 die Möglichkeit, mehrere Submit-Buttons in einem Formular zu haben und hinterher zu unterscheiden, welcher gedrückt wurde?
Diese Möglichkeit gibt es, allein die Browserunterstützung ist etwas problematisch. Mit Hilfe eines formaction-Attributs auf einem Submit-Button kann ein Formular dazu gebracht werden, seine Daten an eine andere URL als die im action-Attribut des <form> notierte zu schicken:
<form action="http://foo.com">
<input type="submit"> <!-- sendet an foo.com -->
<input type="submit" formaction="http://bar.de"> <!-- sendet an bar.de -->
</form>
Schade nur, dass es mit der Browserunterstützung vergleichsweise finster aussieht – IE < 10 und der Android-Browser wissen mit dem Attribut nichts anzufangen. Da hilft wohl höchstens ein JavaScript-Hack …
forEach für getElementsByTagName
Funktioniert forEach() eigentlich auch mit Sachen wie document.querySelectorAll() und document.getElementsByTagName()? Ich habe es mit Opera, Firefox und IE9 probiert und es wird der Fehler „forEach ist keine Funktion“ ausgeworfen. Mit „normalen“ Arrays klappt es …
Dieses Verhalten hat so seine Richtigkeit, wenn es auch nicht besonders hilfreich ist. Es ist tatsächlich so, dass forEach() eine Methode von Arrays ist, aber das, was man von getElementsByTagName() und Konsorten zurückbekommt, sind gar keine Arrays! Stattdessen handelt es sich um NodeLists, die außer der length-Eigenschaft und der Möglichkeit, auf enthaltene Elemente über ihren Index zuzugreifen nichts mit Arrays gemein haben. Sie stammen nicht von Array.prototype ab und daher gibt es für sie auch kein forEach().
„Reparieren“ lässt sich dies (in modernen Browsern), indem man die NodeList in ein Array verwandelt. Einfach die slice()-Methode von Array.prototype ausleihen und sie mittels call() auf die NodeList anwenden:
var nodes = document.getElementsByTagName('div');
var arr = Array.prototype.slice.call(nodes);
typeof arr.forEach; // "function"
In nicht ganz so neuen Browsern (IE8 und älter) hilft eine Schleife:
var nodes = document.getElementsByTagName('div');
var arr = [];
for(var i = 0, l = nodes.length; i < l; i++){
arr.push(nodes[i]);
}
Dieses Prinzip funktioniert mit ziemlich allen Array-ähnlichen Objekten, denen man im so Browser über den Weg läuft (wie z.B. FileList und arguments).
Weitere Fragen?
Eure Fragen zu HTML5, JavaScript und anderen Webtechnologien beantworte ich gerne! Einfach eine E-Mail schreiben oder Formspring bemühen und ein bisschen Geduld haben – falls ich gerade unterwegs bin, kann es mit Antwort manchmal etwas dauern, doch früher oder später schreibe ich garantiert zurück.