Nachdem wir in Teil 1 dieses Artikels die wichtigsten Parts der Indexed Database API kennen gelernt haben und auch erfahren haben, dass dieses Feature bisher nur in Chrome, Firefox und IE 10 zu finden ist, stellt sich die übliche HTML5-Fragen: kann man das Ganze überhaupt benutzen? Ja, man kann. Für die Browser ohne Unterstützung für Indexed DB gibt es gute Polyfills und die wenigen Macken, die die vorhandenen Implementierungen haben, lassen sich recht einfach ausmerzen. Ein wenig problematischer ist der noch herrschende Mangel an Tools und Libraries. Aber alles der Reihe nach …
Polyfill(s) für Safari, Opera und andere
Opera und Safari inklusive Mobile-Varianten unterstützen die Indexed Database API nicht. Was sie allerdings unterstützen, ist Web SQL, dieser aufgegebene Nun-doch-nicht-Standard für relationale Datenbanken im Browser. Es ist dann ziemlich naheliegend, einen Polyfill zu bauen, der die Funktionalität von Indexed DB mittels Web SQL herstellt, was IndexedDBShim.js in gewohnt unkomplizierter Manier macht:
<script src="IndexedDBShim.js"></script>Mit dieser Zeile Code im HTML läuft die Datenspeicherung dann auch in Opera, Safari, iOS, alten Android-Versionen und auch sonst fast allen Browsern, die zwar Web SQL unterstützen, denen es aber an Indexed DB gebricht.
Es gibt neben IndexedDBShim.js noch einen alternativen Polyfill aus der Feder Facebooks, den ich allerdings nicht getestet habe.
Härtefall 1: Android-Browser
Im Standard-Android-Browser (nicht mobile Chrome) ab Version 4 ist Indexed DB implementiert. Dummerweise basiert diese Implementierung aber auf einer älteren, nicht mit anderen Browsern kompatiblen Version der Spezifikationen. Der bequemste Ausweg aus diesem Problemchen ist, den Polyfill statt der nativen, aber fossilen Implementierung zu verwenden, denn Web SQL macht Android sehr viel richtiger als Indexed DB.
Ob eine Implementierung von Indexed DB veraltet ist, lässt sich am Vorhandensein von window.IDBVersionChangeEvent ablesen. Diese Variable wird nur von der aktuellen Version der Spezifikation beschrieben; ein Browser, der sie nicht hat, hat entweder gar keine Indexed DB oder eine alte Version. Der Rest ist dann ganz einfach:
// Keine (aktuelle) Implementierung von Indexed DB vorhanden?
var requireShim = typeof window.IDBVersionChangeEvent == 'undefined';
// WebSQL vorhanden?
var supportsWebSql = typeof window.openDatabase != 'undefined';
if(requireShim && supportsWebSql){
window.shimIndexedDB.__useShim(); // Verwendung des Polyfills erwzingen
}Damit sind Android-Browser und auch alle anderen Fossilien, die eine alte Variante von Indexed DB mit sich herumschleppen, bedient.
Härtefall 2: Tools
Chrome bietet ein komfortables, in den Web Inspector einbgebautes UI zur Betrachtung von Indexed DB-Datenbanken im Resouces-Tab:
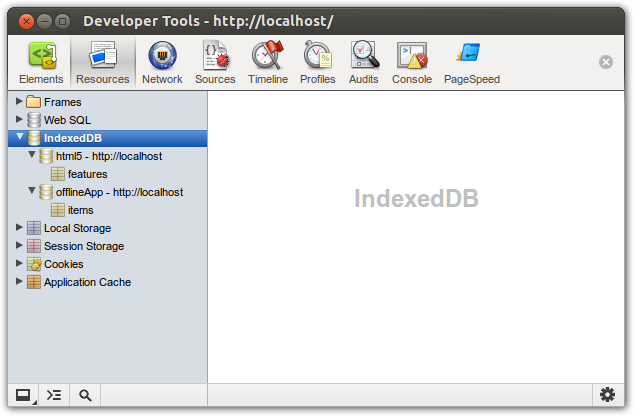
Und das war es dann auch schon mit guten Nachrichten von der Tool-Front, denn weder Firefox noch Internet Explorer können mit nativen Tools aufwarten. Am nächsten kommt man dem im Firefox noch mit dem Addon SQLite Manager, denn unter der Haube speichert dieser Browser die Indexed Database in einer SQLite-Datenbank. Diese befindet sich in aller Regel im Profil-Verzeichnis der jeweiligen Firefox-Users im Unterverzeichnis indexedDB/ und hat den Namen <KRYPTISCHE_ID>.sqlite. Da sich SQLite und Indexed DB in ihrem Wesen stark unterscheiden, ist der SQLite Manager nicht wirklich ein super-komfortables Tool, aber er ist besser als gar nichts.
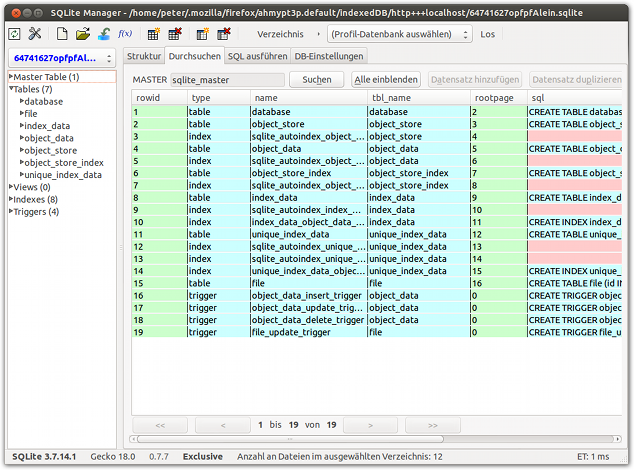
Stichwort „gar nichts“: für den IE 10 scheint es gar kein browserbasiertes Tool zu geben. Das nächstbeste sind sind diverse Ansätze für in HTML eingebaute Scripts, die dann einen Inspector-UI in die Seite rendern. Zu nennen wäre da vor allem der IDBExplorer, den ich allerdings nicht gründlich genug gestestet habe, um eine Aussage über dessen Tauglichkeit zu machen.
Härtefall 3: Libraries
Dem Indexed DB-Universum fehlen noch vernünftige Libraries. Zwar ist die API nicht schlecht, aber mehr Komfort und Funktionalität darf man sich als Entwickler durchaus wünschen. Zum Beispiel wäre ein Möglichkeit zur Definition von Schemata (inklusive Validierung, Defaultwerten und Virtuals) ganz wünschenswert und auch eine etwas mehr an moderne Befindlichkeiten angepasste API (Stichwort Verkettung) würde sicher Abnehmer finden. Außer Ansätzen ist in dieser Richtung aber bisher noch nicht viel zu finden.
Am nächsten kommen dem gewünschten Featureset noch db.js und IDBWrapper, die beide verkettbare APIs herstellen. Statt sich mit Transaktion und onsuccess-Callbacks herumzuschlagen, schreibt man einfach herunter, was man mit der Datenbank anstellen möchte:
// Beispiel mit db.js
server.people.add({
firstName: 'Aaron',
lastName: 'Powell',
answer: 42
}).done(function(item){
// item stored
});Und das wäre eigentlich schon alles, was ich in Sachen Libraries auftreiben konnte. Aus der Ecke der Microsoft-Fans kommt außerdem noch Linq2IndexedDB, das aber in einem Maße unterdokumentiert ist, dass wir am besten so tun, als hätte ich es gar nicht verlinkt.
Fazit
Unter zuhilfenahme aller Polyfills und Tricks sieht es mit der Browserunterstützung für Indexed DB eigentlich vergleichsweise gut aus:
| Browser | Unterstützung ab Version |
|---|---|
| Firefox | 4*† / 16+ |
| Chrome | 11*† / 23* / 24+ |
| Safari | - (< 5.1+) |
| Opera | - (< 12.1+) |
| Internet Explorer | 10+ |
| Mobile Safari | - (< 5.1+) |
| Android Browser | 4.?† (2.1+) |
* Mit Vendor-Prefix
† Implementierung entspricht nicht aktuellen Specs
In Klammern: mit Polyfill
Klar: die üblichen schwarzen Schafe, die alten IE und das, was bei Android als Browser durchgeht, sind mal wieder die Fortschrittsverhinderer. Richtig ruhmvoll ist natürlich auch das Abschneiden von Opera und Safari nicht, aber der recht gute Polyfill (bzw. die verschiedenen Polyfills) lindert den Schmerz doch erheblich. Dramatischer erscheint mir das Fehlen an richtig guten Tools für Indexed DB – die Browser mit nativer Unterstützung sowie interessierte JavaScript-Nerds mit Datenbank-Wissen sollten an dieser Front dringend nachrüsten. Ich hätte gern sowas wie Mongoose für Indexed DB.
Alles in allem lässt sich sagen, dass Indexed Database nach HTML5-Maßstäben eine bereits relativ runde Sache ist. Die Spezifikationen sind recht stabil und die Funktionen in allen Browserfamilien zum funktionieren zu bekommen. Allein in Sachen Tools und Libraries fehlt es noch, aber das sollte ein im Laufe der Zeit lösbares Problem sein.
Ein und Link eine Warnung
Da diese beiden Artikel hier nur einen sehr sehr grober Überblick geben konnten, möchte ich gern noch auf die wie immer erstklassige MDN-Dokumentation zum Thema hinweisen, die aktuell und auch sehr vollständig ist. Und zum Abschluss noch eine Warnung: ähnlich wie die Implementierung im Android-Browser gibt es auch Artikel zu Indexed DB, die auf einer heute veralteten Fassung der Spezifikationen basieren. Diese Artikel kann man daran erkennen, dass in ihnen eine setVersion()-Funktion besprochen wird, die es in der aktuellen Fassung nicht mehr gibt. Wenn ihr also in einem Artikel zu Indexed DB über setVersion() stolpert, lest lieber anderswo weiter.