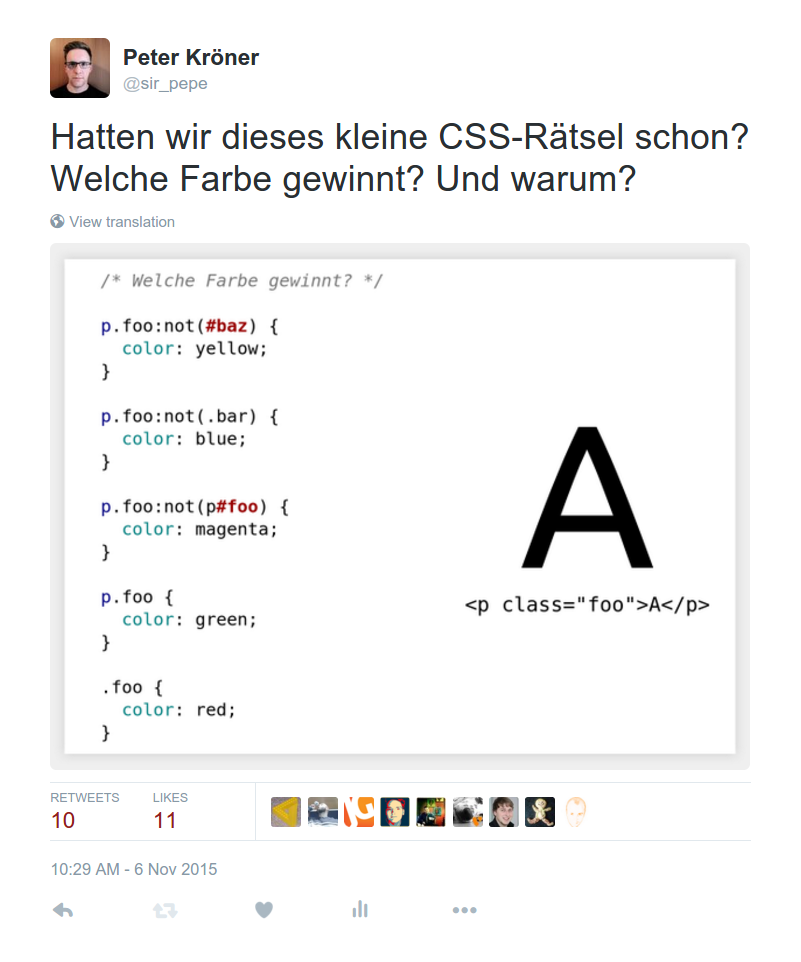
Am Freitag twitterte ich ein kleines CSS-Rätsel und bekam so viele verschiedene Antworten, dass ich an dieser Stelle nochmal die ausführliche (richtige) Antwort aufschreiben möchte.
Die Frage dreht sich darum, welche Farbe der Text im folgenden HTML-Schnipsel erhält …
<p class="foo"> A </p>
… wenn dieses CSS auf ihn losgelassen wird:
p.foo:not(#baz) {
color: yellow;
}
p.foo:not(.bar) {
color: blue;
}
p.foo:not(p#foo) {
color: magenta;
}
p.foo {
color: green;
}
.foo {
color: red;
}
Die meisten Quiz-Teilnehmer tippten auf Magenta und waren erstaunt, in ihren Browsern Gelb zu sehen. Einige wenige tippten auch auf Magenta und sahen es am Ende auch in ihrem Browser. Wie so oft in der Frontend-Entwicklung lautet die richtige Antwort auf dieses Rätsel: es kommt darauf an! Je nachdem welchen Browser man auf den Code loslässt, kommt das eine oder das andere heraus.
Eigentlicher Gegenstand des Rätsels ist die Selektorspezifität. Wären alle Selektoren gleich viel wert, würde die letzte auf ein Element anwendbare CSS-Regel alle anderen überstimmen und der Text würde rot. Doch verschiedene Selektoren haben verschieden viel Gewicht: ID-Selektoren schlagen Klassen-Selektoren, Klassen-Selektoren schlagen Element-Selektoren und kombinierte Selektoren wie z.B. p.foo wiegen einen aus ihren Bestandteilen errechneten Wert (Cheat Sheet). Da unter allen Selektoren im Rätsel der für die rote Farbe der unspezifischste ist, muss der Text eine andere Farbe bekommen. Aber welche?
{kind=link}
Die Spezifität eines Selektors setzt sich aus drei Bestandteilen zusammen:
- A ist die Anzahl aller ID-Selektoren im Selektor
- B ist die Anzahl aller Klassen-, Attribut- und Pseudoklassen-Selektoren
- C ist die Anzahl aller Typ- und Pseudoelement-Selektoren
Die :not()-Pseudoklasse selbst trägt nicht zur Spezifität bei, der in ihr enthaltene Selektor hingegen schon. Der Universal-Selektor * wird ignoriert.
Um zu entscheiden ob ein Selektor spezifischer ist als ein anderer werden die drei Komponenten A, B und C verglichen. Der Selektor A mit dem größeren A-Wert ist spezifischer; bei Gleichstand wird B verglichen und herrscht auch hier Gleichstand, wird C verglichen. Bei kompletter Gleichwertigkeit siegt der zuletzt definierte Selektor.
Berechnen wir doch mal (mit z.B. diesem Tool) die Spezifität aller Selektoren im Rätsel und sortieren sie entsprechend ihres Gewichts:
| Selektor | Spezifität | Farbe |
|---|---|---|
p.foo:not(p#foo) |
(1, 1, 2) | Magenta |
p.foo:not(#baz) |
(1, 1, 1) | Gelb |
p.foo:not(.bar) |
(0, 2, 1) | Blau |
p.foo |
(0, 1, 1) | Grün |
.foo |
(0, 1, 0) | Rot |
Eigentlich klarer Sieg für das Team Magenta, das dank des p#foo in :not() einen Typselektor mehr hat als Gelb. Warum aber erkennt nicht jeder Browser Magenta als Sieger an? Ganz einfach: :not(p#foo) ist erst ab Selectors Level 4 zulässig! In CSS3 kann :not() nur einfache Selektoren (simple selectors, d.h. alleinstehende Typ-, Attribut-, Klassen-, ID-, oder Pseudoklassen-Seletoren) aufnehmen. Der Selektor p#foo ist ein aus zwei Teilen zusammengesetzter compound selector und im Kontext der :not()-Pseudoklasse für alle außer den allermodernsten Browsern unverständlich.
Interessantes Detail am Rande: Selectors Level 4 definiert zwei Selektor-Profile, ein schnelles und ein vollständiges. Wie man erahnen kann, enthält das schnelle Selektor-Profil nicht alle Features des vollständigen und soll vor allem direkt im Browser-Rendering zum Einsatz kommen. Das vollständige Feature-Set ist für die diversen DOM-Selektor-APIs vorgesehen. In beiden Profilen kann die :not()-Pseudoklasse compound selectors verwenden d.h. dieses neue Feature wird universell einsetzbar sein. Nur der Einsatz von komplexen Selektoren, d.h. solchen mit Kombinatoren, ist dem vollständigen Profil vorbehalten.